【SolidWorks】寸法の一括変更
同じサイズの複数穴の径を一気に変更したいという場合に,今まで一つ一つ寸法変更しており,人生の貴重な時間をかなり無駄にしていました. 物事を独習で身に付けようとすると,不合理なフィッティングが生じてしまって,「どうしてその機能使わないの・・・?」という状況がしばしば起こります. 知ってる人からすれば当然のものばかりなのですが,たくさん機能があるソフトウェアだと,そのアイコンは認知してたけどなんかしらんが使ったことなかった...ということがたまにありますよね. 逐一身に付けていくしかない.
等しい値拘束を使いましょう
名無し電気設備(@nanashinanoni__)さんに教えていただきました.感謝. たとえば二つ以上の穴の径を同一にしたい場合は,ShiftまたはCtrlを押しながらクリックして穴を同時選択した状態で,「等しい値拘束」を入れましょう. 一つの寸法を変更すれば残りの寸法も一気に変更されます.
穴は穴ウィザードで作りましょう
ボルト穴は穴ウィザードを使おう.なんかしらんけど通し穴は今まで部品形状スケッチの中で描いていました.これはマジで無駄だった.「なんかしらんけど(不合理な行動)をしていた」というのがありすぎて泣きたくなる.
【ロボティクス】運動学・ヤコビ行列・擬似逆行列の覚え書き
位置・姿勢に関する運動学
各関節にアクチュエータが搭載されたロボットアームを考える.
関節数をとして,各関節変位を
次元ベクトル
で表す.
アームの手先位置と姿勢をベクトル
で表す.
は
次元ベクトルとしておく.ふつう
であるが,運動が平面上に限られて,かつ姿勢角度を問わない場合,
となるといった状況もある.逆に双腕アームを有するロボットで,両手先の位置姿勢を指定したい場合は
自由度になったりする.
ロボットアームを使用する上で,我々はアーム手先の位置・姿勢を直接指定したり,もしくはそれらが何らかの時間的な軌道を追従するように動かすことで,作業を行わせたい. 我々が直接操作できるのは各関節のアクチュエータの変位や速度といった値であるから,各関節を動かしたときに手先がどのように動くか,または手先に目的とする動作を行わせるためには各関節の変位や速度をどのように指定すればよいのかといった,関節-手先の関係を把握しておく必要がある.
手先位置・姿勢は各関節変位の関数として次のように表すことができる.
\begin{align}
\boldsymbol{x}(t)=\boldsymbol{f}\left(\boldsymbol{q}(t)\right)
\end{align}
これが順運動学であり,関数は一般に非線形関数である.たとえば簡単なケースとして,2つの回転関節で構成された平面2自由度アームの手先位置を関節角
と
で表そうとすると,これらを変数とする
と
が出現することからイメージがつく.
順運動学はロボットの幾何学的な設計パラメータから求めることができる.隣接する関節同士の座標変換は簡単に行えるので,たとえばDH記法によって各座標系間のねじれや並進のずれを表現し,関節間の同次変換行列を求めることで任意の座標系から見た手先位置・姿勢を関節変位の関数として表すことが可能である.
逆運動学はの逆関数を手にすることであって,すなわち
\begin{align}
\boldsymbol{q}(t)=\boldsymbol{f}^{-1}\left(\boldsymbol{x}(t)\right)
\end{align}
という関係がわかればよい.しかしながら,先ほどの2自由度アームの例からわかるように,逆三角関数を用いて必要に応じて場合分けをしながら
を求めなければならず,これが6自由度くらいになると大変である.
そこで解析的に逆運動学を解くのではなく,ニュートン法などの反復計算によって解を求めるということがふつう行われる.そこで役に立つのが微分運動学である.
微分運動学
手先自由度と関節数が等しい場合
手先と関節の(角)速度間の関係は線形で書ける.位置についての順運動学の式を時間微分し,表れた係数部分を行列としてまとめることで次の微分順運動学の式が得られる.
\begin{align}
\dot{\boldsymbol{x}}(t)=\boldsymbol{J}\left(\boldsymbol{q}(t)\right)\dot{\boldsymbol{q}}(t)
\end{align}
行列はヤコビ行列である.
手先6自由度に対して関節数が6,といったように
となっている状況であって,さらに特異姿勢でなければ,ヤコビ行列は正方かつ正則となるから,逆行列が存在して,微分逆運動学を求めることができる.
\begin{align}
\dot{\boldsymbol{q}}(t)=\boldsymbol{J}^{-1}\left(\boldsymbol{q}(t)\right)\dot{\boldsymbol{x}}(t)
\end{align}
説明順序が前後するが,特異姿勢とはヤコビ行列が非正則となる状態を意味する.この場合,ヤコビ行列の逆行列は存在しないから,目的とする手先速度を実現するための関節速度が得られず,ロボットは動作することができない.また,逆行列の各要素には行列式の逆数がかかることを思い起こすと,特異姿勢に近い状態では行列式の値がほぼ零であるため,逆行列の各要素は過大な値となる.したがって,
を微小に変化させるだけであっても
が極めて大きい値になり得る.関節速度が過大になるのは安全性やロボット本体にかかる負荷といった観点から考えてもよろしくない.
手先自由度と関節数が異なる場合
手先自由度と関節の数
が異なる場合はどうすればよいのか.
このときヤコビ行列は非正方となり,逆行列を考えることができない.冗長系,すなわち関節の数が多く
となっている場合はヤコビ行列は横長の長方形となるし,
であれば縦長となる.
必要な手先自由度を実現するためには,関節数は自由度の数以上でなければならないから,ふつうは
となるようにロボットアームを作る.運動学的にはこれで十分である.2次元平面上において手先位置を自在に指定したいのに,もし関節が一つしか無いのであれば,手先位置はリンク長で決まる円周上に限定されてしまう(手先位置は2次元ベクトルで表すことができるけれども,運動は1次元である).
また,関節数
はアクチュエータの個数とイコールであるとは限らないことに注意する.
となっているロボットアームにおいても,全ての関節にアクチュエータが搭載されているとは限らない.関節数
未満の個数のアクチュエータを用いる系を劣駆動系と呼ぶ.平面2自由度アームの二つの回転関節のうち,一つにしかアクチュエータが搭載されておらず,もう一つはフリージョイントであるとする.このような場合においても,手先位置は二つの関節角で決まる.すなわち冗長系と劣駆動系は両立する.一つのアクチュエータによって生成される運動によってフリージョイント側の関節角をどのように制御するか,というのはまた別の問題である.
関節数の方が少ない場合:最小二乗法
このときヤコビ行列は縦長となり,連立方程式の数(手先自由度)が未知数(関節速度)の数よりも多い.この場合,すべての方程式を満たす関節速度のセットは存在せず(不能),の関係がもはや成り立たない.そこで,
と
の差をなるべく小さくするような関節速度
を望ましい答えだとみなすという方針を採る.すなわち最小二乗法を用いればよい.
と表すことができたとき,行列
を擬似逆行列と呼ぶ.
最小二乗法では差の二乗和を最小化する.ベクトルの大きさの二乗は自身との内積であるから,目的関数を
\begin{align}
Q=\left(\boldsymbol{J}\left(\boldsymbol{q}\right)\dot{\boldsymbol{q}}-\dot{\boldsymbol{x}}\right)^{T}\left(\boldsymbol{J}\left(\boldsymbol{q}\right)\dot{\boldsymbol{q}}-\dot{\boldsymbol{x}}\right)
\end{align}
とする.合成関数の微分によって
\begin{align}
\frac{\partial Q}{\partial \dot{\boldsymbol{q}}}&=
\frac{\partial}{\partial \dot{\boldsymbol{q}}} \left(\boldsymbol{J}\left(\boldsymbol{q}\right)\dot{\boldsymbol{q}}-\dot{\boldsymbol{x}}\right)
\frac{\partial}{\partial \left(\boldsymbol{J}\left(\boldsymbol{q}\right)\dot{\boldsymbol{q}}-\dot{\boldsymbol{x}}\right)}
\left[ \left(\boldsymbol{J}\left(\boldsymbol{q}\right)\dot{\boldsymbol{q}}-\dot{\boldsymbol{x}}\right)^{T}\left(\boldsymbol{J}\left(\boldsymbol{q}\right)\dot{\boldsymbol{q}}-\dot{\boldsymbol{x}}\right) \right] \\
&=\boldsymbol{J}\left(\boldsymbol{q}\right)^{T} 2\left(\boldsymbol{J}\left(\boldsymbol{q}\right)\dot{\boldsymbol{q}}-\dot{\boldsymbol{x}}\right)\\
&=2\boldsymbol{J}\left(\boldsymbol{q}\right)^{T}\left(\boldsymbol{J}\left(\boldsymbol{q}\right)\dot{\boldsymbol{q}}-\dot{\boldsymbol{x}}\right)
\end{align}
これがゼロになるときの
を求めればよいから,
\begin{align}
2\boldsymbol{J}\left(\boldsymbol{q}\right)^{T}\left(\boldsymbol{J}\left(\boldsymbol{q}\right)\dot{\boldsymbol{q}}-\dot{\boldsymbol{x}}\right) &= 0 \\
\boldsymbol{J}\left(\boldsymbol{q}\right)^{T}\boldsymbol{J}\left(\boldsymbol{q}\right)\dot{\boldsymbol{q}} &=\boldsymbol{J}\left(\boldsymbol{q}\right)^{T} \dot{\boldsymbol{x}}
\end{align}
ここでグラム行列
は
の正方行列であり,
が列フルランクであれば,
であって逆行列を持つ.
したがって
\begin{align}
\dot{\boldsymbol{q}} &=\left(\boldsymbol{J}\left(\boldsymbol{q}\right)^{T}\boldsymbol{J}\left(\boldsymbol{q}\right)\right)^{-1}\boldsymbol{J}\left(\boldsymbol{q}\right)^{T} \dot{\boldsymbol{x}}
\end{align}
としてそれらしい
を得ることができた.このときの
が,
が縦長で列フルランクであるときの擬似逆行列である.
これは順運動学を満たしている(順運動学の式の両辺に左から擬似逆行列を作用させてみればよい).
関節数の方が多い場合:ラグランジュ未定乗数法
この場合はヤコビ行列が横長となり,連立方程式の数(手先自由度)よりも未知数(関節速度)の数が多い.この連立方程式をがんばって解こうとしても,どうしても未知数が定まらないまま残ってしまう(不定).
つまり等式を満たす
が無数に存在する.
このように解が不定の状況では,無数に存在する解に何らかの制約を課すことで一つに絞り込むことができる.
そこでノルム
を最小化することを考える.ただし,このとき等式
が満たされていなければならない.
すなわち等式制約付きの最小化問題を解くことになる.ラグランジュ未定乗数法によって目的関数は
\begin{align}
Q=\dot{\boldsymbol{q}}^{T}\dot{\boldsymbol{q}}+\boldsymbol{\lambda}^{T} \left( \dot{\boldsymbol{x}}(t)-\boldsymbol{J}\left(\boldsymbol{q}(t)\right)\dot{\boldsymbol{q}}(t) \right)
\end{align}
と書ける.
\begin{align}
\frac{\partial Q}{\partial \dot{\boldsymbol{q}}}=
2\dot{\boldsymbol{q}} - \boldsymbol{J}^{T}\boldsymbol{\lambda} &= 0 \\
\dot{\boldsymbol{q}} &= \frac{1}{2} \boldsymbol{J}^{T}\boldsymbol{\lambda}\\
\end{align}
となるから,
.
行列
は
の正方行列であり,
が行フルランクであれば,
であって逆行列を持つ.したがって,
となる.これにより,
\begin{align}
\dot{\boldsymbol{q}} = \frac{1}{2} \boldsymbol{J}^{T}\boldsymbol{\lambda} = \frac{1}{2} \boldsymbol{J}^{T}2\left( \boldsymbol{J} \boldsymbol{J}^{T} \right)^{-1}\dot{\boldsymbol{x}}
=\boldsymbol{J}^{T}\left( \boldsymbol{J} \boldsymbol{J}^{T} \right)^{-1}\dot{\boldsymbol{x}}
\end{align}
を得る.行列
が,
が横長で行フルランクであるときの擬似逆行列である.
\begin{align}
\dot{\boldsymbol{q}}
=\boldsymbol{J}^{T}\left( \boldsymbol{J} \boldsymbol{J}^{T} \right)^{-1}\dot{\boldsymbol{x}}
\end{align}
の両辺に左からを作用させると,順運動学の式となることがわかる.
特異姿勢となってランク落ちした場合
階数因数分解による方法
どちらもランクがの
行列
と
行列
を用いて
と階数因数分解する.
はランク落ちしており,これまでに挙げた手法では擬似逆行列を計算することができない.グラム行列のランクは元の行列のランクに等しく,つまり
だから,
がランク落ちならば
と
もランク落ちとなり,これらの逆行列が存在しないからである.しかしながら,
は列フルランク,
は行フルランクであるから,これらは擬似逆行列を持つ.
したがって
\begin{align}
\boldsymbol{J}^{+}=\left(\boldsymbol{BC}\right)^{+}=\boldsymbol{C}^{+}\boldsymbol{B}^{+}=\boldsymbol{C}^{T}\left( \boldsymbol{C} \boldsymbol{C}^{T} \right)^{-1}\left(\boldsymbol{B}^{T}\boldsymbol{B}\right)^{-1}\boldsymbol{B}^{T}
\end{align}
と
の擬似逆行列を計算することができる.
は
と
のランクが等しいとき成立する.
SR逆行列(Singularity-Robust Inverse)
手先速度を所望の値にすることよりも,特異点付近での安定性を優先する場合,最小化する目的関数を次のように変更すればよい.
\begin{align} Q=\left(\boldsymbol{J}\dot{\boldsymbol{q}}-\dot{\boldsymbol{x}}\right)^{T}\left(\boldsymbol{J}\dot{\boldsymbol{q}}-\dot{\boldsymbol{x}}\right) +\lambda \dot{\boldsymbol{q}}^{T}\dot{\boldsymbol{q}} \end{align}
そうすると結局,
\begin{align}
\dot{\boldsymbol{q}}=\left( \boldsymbol{J}^{T}\boldsymbol{J} + \lambda \boldsymbol{I}\right)^{-1} \boldsymbol{J}^{T} \dot{\boldsymbol{x}}
\end{align}
となる.がランク落ちであっても,
のおかげで
の逆行列は求まる.
減衰因子
は可操作度を用いるなどして,特異姿勢への近さに応じて調整する.
とりあえず一旦ここまで
擬似逆行列については,特異値分解との関係もまとめたい.可操作度を考えるにあたっても必要だし.
参考書籍
- ロボット制御基礎論(Amazon) 冗長アームといえばこれ.
- 実践ロボット制御(Amazon) ロボット制御基礎論をベースにまとめられた新しい本.ロボットアームの入門的内容を概観するのであればこの本から始めてもよいと思う. ただ当たり前のことだが一冊で勉強が完結するということはないので,ロボット制御基礎論などの他の本を一緒に持っておくのがよい.
- “巧みさ”とロボットの力学 プレミアムブックス版(Amazon) 冗長アームやハンドについて,いかに器用な動作を実現するか?というテーマで2008年に書かれた本.深層学習以後,有本先生たちがどのようなことを考えられているのかは,2017年のロボット制御学ハンドブック(Amazon)最終章にまとめられている.
- ヒューマノイドロボット(改訂2版)(Amazon) ヒューマノイドを題材にして逆運動学の数値解法やMATLAB実装例が紹介されており,イメージがつきやすい.
【現代制御】可制御性
はじめに
現代制御,面白いですよね. と言っても私は大人になってから社会人の教養として雰囲気を嗜んだだけなので,教科書を読みながら(フーン...そうなんだ...)程度の感想とともにスルーしてしまっているところが結構あります. 大人になってから独学したので...と言い訳しましたが,それ自体は理解の精度に対して本質的ではなく,仮に大学で履修していたとしても似たようなものだっただろうという気もします.
現代制御では線形時不変システムの可制御性を,可制御行列と呼ばれる正方行列の正則性を調べることによって判定することができます. 教科書によっては「可制御行列がフルランクであれば可制御」,もしくは「可制御行列の行列式が非零であれば可制御」といった書かれ方をされている本がありますが,どれも同じことです(えっ,という方は線形代数の教科書を読み返しましょう). 可制御行列を用いて可制御性が判定できることの証明は,易しい入門書では説明が省略されていることもあります.備忘録としてまとめておきます.
参考書籍
この本は必要な情報のまとまりも良く,個人的に読みやすいと感じています.
線形時不変システムの状態空間表現
さて,1入力1出力である線形時不変システムを考える.
状態方程式と出力方程式は
\begin{align}
\dot{\boldsymbol{x}}(t)&=\boldsymbol{A}\boldsymbol{x}(t)+\boldsymbol{b}u(t) \\
y(t)&=\boldsymbol{c}^T\boldsymbol{x}(t)
\end{align}
である.ここで状態と
および
は
次元のベクトルであって,
は
行列.
状態方程式の解は
\begin{align}
\boldsymbol{x}(t)=e^{\boldsymbol{A}t} \boldsymbol{x}_{0}+ \int_0 ^{t} e^{\boldsymbol{A}(t-\tau)} \boldsymbol{b} u(\tau) d\tau
\end{align}
です.
可制御性とその判定方法
システムが可制御であるとは,制御入力を与えることによって有限の時間で任意の初期状態から目標とする状態へ変化させられることを意味する.
可制御であるかどうかは,の正方行列
が正則であるかどうかによって判定可能.
この行列を可制御行列と呼ぶ.
なぜ可制御性の判定となるのか
必要性
システムが可制御であれば,可制御行列が正則となることを示す.
可制御であるシステムでは,適当な制御入力を与えることで,ある時刻
にて
となるから,
\begin{align} \boldsymbol{x}(t _ f) &=\boldsymbol{x} _ f =e^{\boldsymbol{A}t _ f} \boldsymbol{x} _ 0 + \int _ 0 ^{t _ f} e^{\boldsymbol{A}(t _ f-\tau)} \boldsymbol{b} u(\tau) d\tau \\ e^{\boldsymbol{A}t _ f} \boldsymbol{x} _ 0 - \boldsymbol{x} _ f &=-\int _ 0 ^{t _ f} e^{\boldsymbol{A}(t _ f-\tau)} \boldsymbol{b} u(\tau) d\tau \end{align}
ここで,行列指数関数の性質として,であることに注意する.これを使って上式を書き換えると,
\begin{align}
\boldsymbol{x} _ 0 - e^{-\boldsymbol{A}t _ f}\boldsymbol{x} _ f &=-e^{-\boldsymbol{A}t _ f}\int _ 0 ^{t _ f} e^{\boldsymbol{A}(t _ f-\tau)} \boldsymbol{b} u(\tau) d\tau \\
&=-\int _ 0 ^{t _ f} e^{-\boldsymbol{A}t _ f+\boldsymbol{A}(t _ f-\tau)} \boldsymbol{b} u(\tau) d\tau \\
&=-\int _ 0 ^{t _ f} e^{-\boldsymbol{A}\tau} \boldsymbol{b} u(\tau) d\tau
\end{align}
となる.
また,行列指数関数は適当な時間関数を係数として個の項の和に展開できる.
\begin{align}
e^{\boldsymbol{A}t} = r _ 0 (t) \boldsymbol{I} + r _ 1 (t) \boldsymbol{A} + \cdots + r _ {n-1}(t)\boldsymbol{A}^{n-1} \\
e^{-\boldsymbol{A}t} = r _ 0 (-t) \boldsymbol{I} + r _ 1 (-t) \boldsymbol{A} + \cdots + r _ {n-1}(-t)\boldsymbol{A}^{n-1}
\end{align}
これを使って
\begin{align}
\boldsymbol{x} _ 0 - e^{-\boldsymbol{A}t _ f}\boldsymbol{x} _ f &=-\int _ 0 ^{t _ f} \left(r _ 0 (-\tau) \boldsymbol{I} + r _ 1 (-\tau) \boldsymbol{A} + \cdots + r _ {n-1}(-\tau)\boldsymbol{A}^{n-1} \right) \boldsymbol{b} u(-\tau) d\tau \\
&= \left( -\int _ 0 ^{t _ f} r _ 0 (-\tau) \boldsymbol{b} u(\tau) d\tau \right) + \cdots +
\left( -\int _ 0 ^{t _ f} r _ {n-1} (-\tau) \boldsymbol{A}^{n-1} \boldsymbol{b} u(\tau) d\tau \right) \\
&= s _ 0 \boldsymbol{b}+ \cdots +
s _ {n-1} \boldsymbol{A}^{n-1} \boldsymbol{b} \\
&=
\begin{bmatrix}
\boldsymbol{b} & \boldsymbol{A}\boldsymbol{b} & \cdots & \boldsymbol{A}^{n-1}\boldsymbol{b}
\end{bmatrix}
\begin{bmatrix}
s _ 0 \\ s _ 1 \\ \vdots \\ s _ {n-1}
\end{bmatrix}
= \boldsymbol{U}_c \boldsymbol{s}
\end{align}
と書ける.ただし,途中で
\begin{align}
s _ i = -\int _ 0 ^{t _ f} r _ i (-\tau) u(\tau) d\tau
\end{align}
とおいた.
\begin{align}
\boldsymbol{x} _ 0 - e^{-\boldsymbol{A}t _ f}\boldsymbol{x} _ f
&=
\boldsymbol{U}_c \boldsymbol{s}
\end{align}
ここで登場したと
で構成されている行列
が可制御行列である.
上式の左辺は
次元ベクトルであり,
も同じく
次元ベクトルであるから,この可制御行列はフルランクでなければならない.
(可制御行列が非正則,すなわちランク落ちしていると,右辺の次元は
よりも小さくなり等式が成立しない.)
十分性
可制御行列が正則であれば,システムが可制御であることを示す.
(つづく)
【モデル予測制御】ステップ応答のモデル推定値を有限個の和で表現する
目的
モデル予測制御の学習のために参考資料を読んでいたところ,サラッと出て来たステップ応答の有限和の表現(式(10))で躓いてしまった.備忘のために式の導出のノートを残しておく.
※というわけで,モデル予測制御と銘打っていますがモデル予測制御のモの字も出て来ません.私も悲しいのです.あしからず.
参考資料
- 加納 学, 大嶋 正裕, モデル予測制御-II : 線形モデル予測制御, システム/制御/情報, 2002, 46 巻, 7 号, p. 418-424
概要
- 足して引く(正味ゼロ)操作によって和の書き換えを行う.
- 入力が加えられてから,時間
以上経過した後の応答は一定値に収束すると仮定する.事前に定めたこの仮定によって,
の無限和の項を消す.
本題
時刻でのステップ応答として,次に示す式(7)を得る.
ここで第1項が現在時刻以降の入力による応答であり,第2項は時刻
以前の過去の入力による応答である.
モデル予測制御では制御入力区間を定めて,時刻
以降の入力のうち,時刻
までの操作量
を求める.
以降は変化させずに
のままとする.
すなわち,
以上から式(7)は次のように書き直せる.(式9)
モデルによる将来の推定値
を計算するためには無限個の過去の操作量が必要となってしまう.現実のアルゴリズムとして実装するために,第2項の無限個の和を有限個の和に書き直したい.
第2項は次のように書き直せる.
\begin{align} \sum _ {k=1}^{\infty}a _ {j+k}\Delta u(t-k) &= \sum _ {k=1}^{s-1}a _ {j+k}\Delta u(t-k) + \sum _ {k=s}^{\infty}a _ {j+k}\Delta u(t-k) \\ &= \sum _ {k=1}^{s-1}(a _ {j+k}-a _ k+a _ k)\Delta u(t-k) + \sum _ {k=s}^{\infty}a _ {j+k}\Delta u(t-k) \\ &= \sum _ {k=1}^{s-1}a _ k\Delta u(t-k) + \sum _ {k=1}^{s-1}(a _ {j+k}-a _ k)\Delta u(t-k) + \sum _ {k=s}^{\infty}a _ {j+k}\Delta u(t-k) \\ &= \sum _ {k=1}^{s-1}a _ k\Delta u(t-k) + \sum _ {k=1}^{s-1}(a _ {j+k}-a _ k)\Delta u(t-k) + \sum _ {k=s}^{\infty}a _ {j+k}\Delta u(t-k) + \sum _ {k=s}^{\infty}a _ {k}\Delta u(t-k) - \sum _ {k=s}^{\infty}a _ {k}\Delta u(t-k) \\ &= \left (\sum _ {k=1}^{s-1}a _ k \Delta u(t-k) + \sum _ {k=s}^{\infty}a _ {k}\Delta u(t-k) \right) + \sum _ {k=1}^{s-1}(a _ {j+k}-a _ k)\Delta u(t-k) + \left( \sum _ {k=s}^{\infty}a _ {j+k}\Delta u(t-k) - \sum _ {k=s}^{\infty}a _ {k}\Delta u(t-k) \right) \\ &= \sum _ {k=1}^{\infty}a _ k \Delta u(t-k) + \sum _ {k=1}^{s-1}(a _ {j+k}-a _ k)\Delta u(t-k) + \sum _ {k=s}^{\infty}(a _ {j+k}-a _ {k})\Delta u(t-k) \\ &= y _ M(t) + \sum _ {k=1}^{s-1}(a _ {j+k}-a _ k)\Delta u(t-k) + \sum _ {k=s}^{\infty}(a _ {j+k}-a _ {k})\Delta u(t-k) \\ \end{align}
ここで,上の式の第3項は時刻から
ステップ以上過去の入力による成分である.
ステップ経過すると,応答は一定値になると仮定した.すなわち,
であった.第3項の応答係数はそれぞれ
\begin{align} &a _ {j+s}, a _ {j+s+1}, a _ {j+s+2}, \cdots \\ &a _ {s}, a _ {s+1}, a _ {s+2}, \cdots \end{align}
であり,添え字は全て以上であるから,応答係数は全て
になる.したがって,差
となり,第3項は消える.
以上を踏まえて,計算結果を元の式(9)に戻すと,
となって,これは式(10)に一致した.
多次元正規分布の条件付き分布
はじめに
ガウス過程回帰を導出する上で必要になる多次元正規分布の条件付き分布についてまとめておく. 教科書「ガウス過程と機械学習」を参考に,式変形の各ステップをなるべく省略せずに記した.
参考資料
持橋先生,大場先生の「ガウス過程と機械学習」先行公開 (γ2版)の第2章. 19年3月発売予定らしいが,サポートページにて一部公開されている.先行公開原稿が素晴らしいのに加えて,サポートページの内容の充実っぷりがすごい. ただ,(私の勘違いかもしれないが)19年2/4現在において,公開版では後述のように微妙な誤りがあるので注意.正式版では修正されることを期待.
19/03/12追記:書籍版では一部修正されていました.また,正誤表がサポートページにて公開されています.
")
多次元正規分布
次元のベクトル
が平均
,共分散行列
の正規分布に従うとき,以下のように表す.
\begin{align} \boldsymbol{x}&\sim \mathcal{N}\left(\boldsymbol{x}|\boldsymbol{\mu}, \boldsymbol{\Sigma} \right) \\ \mathcal{N}(\boldsymbol{x}|\boldsymbol{\mu},\boldsymbol{\Sigma})&=\frac{1}{\left(\sqrt{2\pi}^D \sqrt{|\boldsymbol{\Sigma}|}\right)}\exp\left(-\frac{1}{2}\left(\boldsymbol{x}-\boldsymbol{\mu}\right)^T \boldsymbol{\Sigma}^{-1} \left(\boldsymbol{x}-\boldsymbol{\mu}\right)\right) \end{align}
多次元正規分布の条件付き分布
を二つのベクトル
と
に分ける.
から,最初の
次元
を抜き出し,残りを
とする.
このときを固定したときの条件付き分布
は次のように書ける.
\begin{align} p\left(\boldsymbol{x} _ 2|\boldsymbol{x} _ 1 \right)=\mathcal{N}\left(\boldsymbol{\mu} _ 2+\boldsymbol{\Sigma} _ {21}\boldsymbol{\Sigma} _ {11}^{-1}\left(\boldsymbol{x} _ 1-\boldsymbol{\mu} _ 1\right), \boldsymbol{\Sigma} _ {22}-\boldsymbol{\Sigma} _ {21}\boldsymbol{\Sigma} _ {11}^{-1}\boldsymbol{\Sigma} _ {12}\right) \ \end{align}
導出
同時分布と条件付き分布の関係(乗法定理)は
\begin{align} p\left(\boldsymbol{x} _ 1,\boldsymbol{x} _ 2 \right)=p\left(\boldsymbol{x} _ 2|\boldsymbol{x} _ 1 \right)p\left(\boldsymbol{x} _ 1 \right)\end{align}
だった.条件付き分布は
\begin{align} p\left(\boldsymbol{x} _ 2|\boldsymbol{x} _ 1 \right)=\frac{p\left(\boldsymbol{x} _ 1,\boldsymbol{x} _ 2 \right)}{p\left(\boldsymbol{x} _ 1\right)} \ \end{align}
であり,今は条件として固定されているので,
の関数
は
に比例している(分母の
には依存しない).
すなわち
である.
さて,であった.同時分布
は
と
が「同時に」得られる確率なのだから,
である.
を二つのベクトルに分割したので,
と
も二つに分割して,次のように表すことができる.
\begin{align} \boldsymbol{x}= \left( \begin{array}{c} \boldsymbol{x} _ {1} \\ \boldsymbol{x} _ {2} \end{array} \right) \sim \mathcal{N}\left( \left( \begin{array}{c} \boldsymbol{\mu} _ {1} \\ \boldsymbol{\mu} _ {2} \end{array} \right) , \left( \begin{array}{cc} \boldsymbol{\Sigma} _ {11} & \boldsymbol{\Sigma} _ {12}\\ \boldsymbol{\Sigma} _ {21} & \boldsymbol{\Sigma} _ {22} \end{array} \right) \right) \end{align}
精度行列,すなわち共分散行列の逆行列を次のように定義する.
\begin{align} \Lambda= \begin{pmatrix} \boldsymbol{\Lambda} _ {11} & \boldsymbol{\Lambda} _ {12} \\ \boldsymbol{\Lambda} _ {21} & \boldsymbol{\Lambda} _ {22} \end{pmatrix} = \begin{pmatrix} \boldsymbol{\Sigma} _ {11} & \boldsymbol{\Sigma} _ {12} \\ \boldsymbol{\Sigma} _ {21} & \boldsymbol{\Sigma} _ {22} \end{pmatrix}^{-1} \end{align}
この精度行列を用いることによって,元の正規分布を次のように表せる.
\begin{align} \mathcal{N}\left(\boldsymbol{x}|\boldsymbol{\mu}, \boldsymbol{\Sigma} \right) = p\left(\boldsymbol{x} _ 2,\boldsymbol{x} _ 1 \right) &\propto \exp\left(-\frac{1}{2}\left(\boldsymbol{x}-\boldsymbol{\mu}\right)^T \boldsymbol{\Sigma}^{-1} \left(\boldsymbol{x}-\boldsymbol{\mu}\right)\right) \\ &= \exp\left(-\frac{1}{2}\left(\boldsymbol{x}-\boldsymbol{\mu}\right)^T \boldsymbol{\Lambda} \left(\boldsymbol{x}-\boldsymbol{\mu}\right)\right) \\ &= \exp\left(-\frac{1}{2} \begin{pmatrix} \boldsymbol{x} _ {1} - \boldsymbol{\mu} _ {1} \\ \boldsymbol{x} _ {2} - \boldsymbol{\mu} _ {2} \end{pmatrix}^T \begin{pmatrix} \boldsymbol{\Lambda} _ {11} & \boldsymbol{\Lambda} _ {12}\\ \boldsymbol{\Lambda} _ {21} & \boldsymbol{\Lambda} _ {22} \end{pmatrix} \begin{pmatrix} \boldsymbol{x} _ {1} - \boldsymbol{\mu} _ {1} \\ \boldsymbol{x} _ {2} - \boldsymbol{\mu} _ {2} \end{pmatrix} \right) \end{align}
次にの括弧の中を展開したいのだが,要素がブロックに分割されたベクトルの転置については注意しておこう.次に示すように,中身を転置した上で,さらに各ブロックについて転置を取る必要がある.
\begin{align} \begin{pmatrix} \boldsymbol{x} _ {1} - \boldsymbol{\mu} _ {1} \\ \boldsymbol{x} _ {2} - \boldsymbol{\mu} _ {2} \end{pmatrix}^T = \begin{pmatrix} \left( \boldsymbol{x} _ {1} - \boldsymbol{\mu} _ {1} \right)^T & \left( \boldsymbol{x} _ {2} - \boldsymbol{\mu} _ {2} \right)^T \end{pmatrix} \end{align}
したがって,
\begin{align} \begin{pmatrix} \boldsymbol{x} _ {1} - \boldsymbol{\mu} _ {1} \\ \boldsymbol{x} _ {2} - \boldsymbol{\mu} _ {2} \end{pmatrix}^T \begin{pmatrix} \boldsymbol{\Lambda} _ {11} & \boldsymbol{\Lambda} _ {12}\\ \boldsymbol{\Lambda} _ {21} & \boldsymbol{\Lambda} _ {22} \end{pmatrix}\begin{pmatrix} \boldsymbol{x} _ {1} - \boldsymbol{\mu} _ {1} \\ \boldsymbol{x} _ {2} - \boldsymbol{\mu} _ {2} \end{pmatrix}&= \begin{pmatrix} \left( \boldsymbol{x} _ {1} - \boldsymbol{\mu} _ {1} \right)^T & \left( \boldsymbol{x} _ {2} - \boldsymbol{\mu} _ {2} \right)^T \end{pmatrix}\begin{pmatrix} \boldsymbol{\Lambda} _ {11} \left( \boldsymbol{x} _ {1} - \boldsymbol{\mu} _ {1} \right) +\boldsymbol{\Lambda} _ {12} \left( \boldsymbol{x} _ {2} - \boldsymbol{\mu} _ {2} \right) \\ \boldsymbol{\Lambda} _ {21} \left( \boldsymbol{x} _ {1} - \boldsymbol{\mu} _ {1} \right) +\boldsymbol{\Lambda} _ {22} \left( \boldsymbol{x} _ {2} - \boldsymbol{\mu} _ {2} \right) \end{pmatrix} \\ &= \left( \boldsymbol{x} _ {1} - \boldsymbol{\mu} _ {1} \right)^T \boldsymbol{\Lambda} _ {11} \left( \boldsymbol{x} _ {1} - \boldsymbol{\mu} _ {1} \right) + \left( \boldsymbol{x} _ {1} - \boldsymbol{\mu} _ {1} \right)^T \boldsymbol{\Lambda} _ {12} \left( \boldsymbol{x} _ {2} - \boldsymbol{\mu} _ {2} \right)+ \\ & \hspace{14pt} \left( \boldsymbol{x} _ {2} - \boldsymbol{\mu} _ {2} \right)^T \boldsymbol{\Lambda} _ {21} \left( \boldsymbol{x} _ {1} - \boldsymbol{\mu} _ {1} \right) + \left( \boldsymbol{x} _ {2} - \boldsymbol{\mu} _ {2} \right)^T \boldsymbol{\Lambda} _ {22} \left( \boldsymbol{x} _ {2} - \boldsymbol{\mu} _ {2} \right) \\ &= \left( \boldsymbol{x} _ {1} - \boldsymbol{\mu} _ {1} \right)^T \boldsymbol{\Lambda} _ {11} \left( \boldsymbol{x} _ {1} - \boldsymbol{\mu} _ {1} \right) + 2\left( \boldsymbol{x} _ {1} - \boldsymbol{\mu} _ {1} \right)^T \boldsymbol{\Lambda} _ {21} \left( \boldsymbol{x} _ {2} - \boldsymbol{\mu} _ {2} \right)+ \\ & \hspace{14pt} \left( \boldsymbol{x} _ {2} - \boldsymbol{\mu} _ {2} \right)^T \boldsymbol{\Lambda} _ {22} \left( \boldsymbol{x} _ {2} - \boldsymbol{\mu} _ {2} \right) \\ \end{align}
最後の式変形では,であり,中央の二つの項が同一であることから導かれる.
ここで一旦,
の中に戻して眺めてみる.
の括弧内の和は,それぞれの
の積に分解できるから,
\begin{align} &\exp\left( \left( \boldsymbol{x} _ {1} - \boldsymbol{\mu} _ {1} \right)^T \boldsymbol{\Lambda} _ {11} \left( \boldsymbol{x} _ {1} - \boldsymbol{\mu} _ {1} \right) + 2\left( \boldsymbol{x} _ {1} - \boldsymbol{\mu} _ {1} \right)^T \boldsymbol{\Lambda} _ {21} \left( \boldsymbol{x} _ {2} - \boldsymbol{\mu} _ {2} \right) + \left( \boldsymbol{x} _ {2} - \boldsymbol{\mu} _ {2} \right)^T \boldsymbol{\Lambda} _ {22} \left( \boldsymbol{x} _ {2} - \boldsymbol{\mu} _ {2} \right) \right)\\ &= \exp\left( \left( \boldsymbol{x} _ {1} - \boldsymbol{\mu} _ {1} \right)^T \boldsymbol{\Lambda} _ {11} \left( \boldsymbol{x} _ {1} - \boldsymbol{\mu} _ {1} \right) \right) \exp\left( 2\left( \boldsymbol{x} _ {1} - \boldsymbol{\mu} _ {1} \right)^T \boldsymbol{\Lambda} _ {21} \left( \boldsymbol{x} _ {2} - \boldsymbol{\mu} _ {2} \right) + \left( \boldsymbol{x} _ {2} - \boldsymbol{\mu} _ {2} \right)^T \boldsymbol{\Lambda} _ {22} \left( \boldsymbol{x} _ {2} - \boldsymbol{\mu} _ {2} \right) \right)\\ \end{align}
となる.を省略していることに注意.
ここでには
が含まれておらず,
はこの項に依存しない.したがって引き続き比例関係のみに注目すれば,
\begin{align} p\left(\boldsymbol{x} _ 2|\boldsymbol{x} _ 1 \right) &\propto p\left(\boldsymbol{x} _ 1,\boldsymbol{x} _ 2 \right)\\ &\propto \exp\left( -\frac{1}{2} \left( 2\left( \boldsymbol{x} _ {1} - \boldsymbol{\mu} _ {1} \right)^T \boldsymbol{\Lambda} _ {21} \left( \boldsymbol{x} _ {2} - \boldsymbol{\mu} _ {2} \right) + \left( \boldsymbol{x} _ {2} - \boldsymbol{\mu} _ {2} \right)^T \boldsymbol{\Lambda} _ {22} \left( \boldsymbol{x} _ {2} - \boldsymbol{\mu} _ {2} \right) \right) \right) \end{align}
となる.の括弧の中身をさらに展開しよう.
\begin{align} &2\left( \boldsymbol{x} _ {1} - \boldsymbol{\mu} _ {1} \right)^T \boldsymbol{\Lambda} _ {21} \left( \boldsymbol{x} _ {2} - \boldsymbol{\mu} _ {2} \right) + \left( \boldsymbol{x} _ {2} - \boldsymbol{\mu} _ {2} \right)^T \boldsymbol{\Lambda} _ {22} \left( \boldsymbol{x} _ {2} - \boldsymbol{\mu} _ {2} \right) \\ &= \boldsymbol{x} _ {2}^T \boldsymbol{\Lambda} _ {22} \boldsymbol{x} _ {2} - \boldsymbol{x} _ {2}^T \boldsymbol{\Lambda} _ {22} \boldsymbol{\mu} _ {2} - \boldsymbol{\mu} _ {2}^T \boldsymbol{\Lambda} _ {22} \boldsymbol{x} _ {2} + \boldsymbol{\mu} _ {2}^T \boldsymbol{\Lambda} _ {22} \boldsymbol{\mu} _ {2} + \\ &\hspace{15pt} 2\boldsymbol{x} _ {1}^T \boldsymbol{\Lambda} _ {21} \boldsymbol{x} _ {2} -2\boldsymbol{x} _ {1}^T \boldsymbol{\Lambda} _ {21} \boldsymbol{\mu} _ {2} -2\boldsymbol{\mu} _ {1}^T \boldsymbol{\Lambda} _ {21} \boldsymbol{x} _ {2} +2\boldsymbol{\mu} _ {1}^T \boldsymbol{\Lambda} _ {21} \boldsymbol{\mu} _ {2} \end{align}
ここで,が含まれていない項は,先ほどと同様に独立な
の項として分離することができ,ただの係数となって比例関係から無視することができる.そうすると生き残る項は
\begin{align} &\boldsymbol{x} _ {2}^T \boldsymbol{\Lambda} _ {22} \boldsymbol{x} _ {2} - \boldsymbol{x} _ {2}^T \boldsymbol{\Lambda} _ {22} \boldsymbol{\mu} _ {2} - \boldsymbol{\mu} _ {2}^T \boldsymbol{\Lambda} _ {22} \boldsymbol{x} _ {2} + 2\boldsymbol{x} _ {1}^T \boldsymbol{\Lambda} _ {21} \boldsymbol{x} _ {2} -2\boldsymbol{\mu} _ {1}^T \boldsymbol{\Lambda} _ {21} \boldsymbol{x} _ {2} \\ &= \boldsymbol{x} _ {2}^T \boldsymbol{\Lambda} _ {22} \boldsymbol{x} _ {2} - \boldsymbol{x} _ {2}^T \boldsymbol{\Lambda} _ {22} \boldsymbol{\mu} _ {2} - \boldsymbol{\mu} _ {2}^T \boldsymbol{\Lambda} _ {22} \boldsymbol{x} _ {2} + 2\left(\boldsymbol{x} _ {1}^T-\boldsymbol{\mu} _ {1}^T\right) \boldsymbol{\Lambda} _ {21} \boldsymbol{x} _ {2} \\ &= \boldsymbol{x} _ {2}^T \boldsymbol{\Lambda} _ {22} \boldsymbol{x} _ {2} - \boldsymbol{x} _ {2}^T \boldsymbol{\Lambda} _ {22} \boldsymbol{\mu} _ {2} - \boldsymbol{\mu} _ {2}^T \boldsymbol{\Lambda} _ {22} \boldsymbol{x} _ {2} + 2\left(\boldsymbol{x} _ {1}-\boldsymbol{\mu} _ {1}\right)^T \boldsymbol{\Lambda} _ {21} \boldsymbol{x} _ {2} \end{align}
ここで,各項はそれぞれ内積なので,転置を取っても値が変わらない.また,精度行列は対称行列であることから,
\begin{align} \boldsymbol{\mu} _ {2}^T \boldsymbol{\Lambda} _ {22} \boldsymbol{x} _ {2} &= \left( \boldsymbol{\mu} _ {2}^T \boldsymbol{\Lambda} _ {22} \boldsymbol{x} _ {2} \right)^T \\ &= \boldsymbol{x} _ {2}^T \boldsymbol{\Lambda} _ {22} \boldsymbol{\mu} _ {2} \\ 2\left(\boldsymbol{x} _ {1}-\boldsymbol{\mu} _ {1}\right)^T \boldsymbol{\Lambda} _ {21} \boldsymbol{x} _ {2} &= \left( 2\left(\boldsymbol{x} _ {1}-\boldsymbol{\mu} _ {1}\right)^T \boldsymbol{\Lambda} _ {21} \boldsymbol{x} _ {2} \right)^T \\ &= 2\boldsymbol{x} _ {2}^T \boldsymbol{\Lambda} _ {21} \left(\boldsymbol{x} _ {1}-\boldsymbol{\mu} _ {1}\right) \end{align}
となる.そうすると上の式は,次のように書ける.
\begin{align} &\boldsymbol{x} _ {2}^T \boldsymbol{\Lambda} _ {22} \boldsymbol{x} _ {2} - \boldsymbol{x} _ {2}^T \boldsymbol{\Lambda} _ {22} \boldsymbol{\mu} _ {2} - \boldsymbol{\mu} _ {2}^T \boldsymbol{\Lambda} _ {22} \boldsymbol{x} _ {2} + 2\left(\boldsymbol{x} _ {1}-\boldsymbol{\mu} _ {1}\right)^T \boldsymbol{\Lambda} _ {21} \boldsymbol{x} _ {2} \\ &= \boldsymbol{x} _ {2}^T \boldsymbol{\Lambda} _ {22} \boldsymbol{x} _ {2} - 2\boldsymbol{x} _ {2}^T \boldsymbol{\Lambda} _ {22} \boldsymbol{\mu} _ {2} + 2\boldsymbol{x} _ {2}^T \boldsymbol{\Lambda} _ {21} \left(\boldsymbol{x} _ {1}-\boldsymbol{\mu} _ {1}\right) \\ &= \boldsymbol{x} _ {2}^T \boldsymbol{\Lambda} _ {22} \boldsymbol{x} _ {2} -2\boldsymbol{x} _ {2}^T \left( \boldsymbol{\Lambda} _ {22} \boldsymbol{\mu} _ {2} +\boldsymbol{\Lambda} _ {21} \left(\boldsymbol{x} _ {1}-\boldsymbol{\mu} _ {1}\right) \right) \end{align}
見やすくするためにベクトルを
とおく.
そうして上の式を平方完成すると,
\begin{align} &\boldsymbol{x} _ {2}^T \boldsymbol{\Lambda} _ {22} \boldsymbol{x} _ {2} -2\boldsymbol{x} _ {2}^T \boldsymbol{a} = \left( \boldsymbol{x} _ {2} - \boldsymbol{\Lambda} _ {22}^{-1} \boldsymbol{a} \right)^T \boldsymbol{\Lambda} _ {22} \left( \boldsymbol{x} _ {2} - \boldsymbol{\Lambda} _ {22}^{-1} \boldsymbol{a} \right) - \boldsymbol{a}^T \boldsymbol{\Lambda} _ {22}^{-1} \boldsymbol{a} \end{align}
ここで,は
を含んでいないから,これまでと同様に独立な
の項として分離することができ,ただの係数となって比例関係から無視することができる.
結局,比例関係は次のようになる.
\begin{align} p\left(\boldsymbol{x} _ 2|\boldsymbol{x} _ 1 \right) &\propto p\left(\boldsymbol{x} _ 1,\boldsymbol{x} _ 2 \right)\\ &\propto \exp\left( -\frac{1}{2} \left( \boldsymbol{x} _ {2} - \boldsymbol{\Lambda} _ {22}^{-1} \boldsymbol{a} \right)^T \boldsymbol{\Lambda} _ {22} \left( \boldsymbol{x} _ {2} - \boldsymbol{\Lambda} _ {22}^{-1} \boldsymbol{a} \right) \right) \end{align}
したがって,は次の正規分布に従う.共分散行列が
の逆行列であることに注意.
\begin{align} p\left(\boldsymbol{x} _ 2|\boldsymbol{x} _ 1 \right) &\sim \mathcal{N} \left( \boldsymbol{\Lambda} _ {22}^{-1} \boldsymbol{a} , \boldsymbol{\Lambda} _ {22}^{-1} \right) \\ &= \mathcal{N} \left( \boldsymbol{\Lambda} _ {22}^{-1} (\boldsymbol{\Lambda} _ {22} \boldsymbol{\mu} _ {2} +\boldsymbol{\Lambda} _ {21} \left(\boldsymbol{x} _ {1}-\boldsymbol{\mu} _ {1}\right) , \boldsymbol{\Lambda} _ {22}^{-1} \right) \\ &= \mathcal{N} \left( \boldsymbol{\mu} _ {2} +\boldsymbol{\Lambda} _ {22}^{-1}\boldsymbol{\Lambda} _ {21} \left(\boldsymbol{x} _ {1}-\boldsymbol{\mu} _ {1}\right) , \boldsymbol{\Lambda} _ {22}^{-1} \right) \\ \end{align}
精度行列を共分散行列
に戻したいのだが,そのためにブロック行列の逆行列を求める公式を使う.
とおくと,
\begin{align} \Lambda= \begin{pmatrix} \boldsymbol{\Lambda} _ {11} & \boldsymbol{\Lambda} _ {12}\\ \boldsymbol{\Lambda} _ {21} & \boldsymbol{\Lambda} _ {22} \end{pmatrix} = \begin{pmatrix} \boldsymbol{\Sigma} _ {11} & \boldsymbol{\Sigma} _ {12}\\ \boldsymbol{\Sigma} _ {21} & \boldsymbol{\Sigma} _ {22} \end{pmatrix}^{-1} \end{align}
において,
\begin{align} \boldsymbol{\Lambda} _ {22} &= \boldsymbol{M} = \left( \boldsymbol{\Sigma} _ {22}-\boldsymbol{\Sigma} _ {21}\boldsymbol{\Sigma} _ {11}^{-1}\boldsymbol{\Sigma} _ {21} \right)^{-1} \\ \boldsymbol{\Lambda} _ {21} &= -\boldsymbol{M}\boldsymbol{\Sigma} _ {21}\boldsymbol{\Sigma} _ {11}^{-1} \end{align}
となる.二つを組み合わせれば
\begin{align} \boldsymbol{\Lambda} _ {22}^{-1} \boldsymbol{\Lambda} _ {21} &= -\boldsymbol{\Sigma} _ {21}\boldsymbol{\Sigma} _ {11}^{-1} \end{align}
であるから,
\begin{align} p\left(\boldsymbol{x} _ 2|\boldsymbol{x} _ 1 \right) &\sim \mathcal{N} \left( \boldsymbol{\mu} _ {2} +\boldsymbol{\Lambda} _ {22}^{-1}\boldsymbol{\Lambda} _ {21} \left(\boldsymbol{x} _ {1}-\boldsymbol{\mu} _ {1}\right) , \boldsymbol{\Lambda} _ {22}^{-1} \right) \\ &= \mathcal{N} \left( \boldsymbol{\mu} _ {2} -\boldsymbol{\Sigma} _ {21}\boldsymbol{\Sigma} _ {11}^{-1} \left(\boldsymbol{x} _ {1}-\boldsymbol{\mu} _ {1}\right) , \boldsymbol{\Sigma} _ {22}-\boldsymbol{\Sigma} _ {21}\boldsymbol{\Sigma} _ {11}^{-1}\boldsymbol{\Sigma} _ {21} \right) \\ \end{align}
に辿り付く.これがゴールである.完.
誤植?
19年2/4現在において,参考資料の先行公開版では微妙な誤りが見られた.少し混乱してしまったので,一応まとめておく.(私の勘違いや計算ミスだったらご指摘ください)
19/03/12追記:書籍版では一部修正されていました.
平方完成の直前,式(2.57)の6行目(γ2版)式(2.56)の5行目(書籍版)
の中身にだけ注目する.
\begin{align} \boldsymbol{x} _ {2}^T \boldsymbol{\Lambda} _ {22} \boldsymbol{x} _ {2} -2\boldsymbol{x} _ {2}^T \left( \boldsymbol{\Lambda} _ {22} \boldsymbol{\mu} _ {2} +\boldsymbol{\Lambda} _ {21} \left(\boldsymbol{x} _ {1}-\boldsymbol{\mu} _ {1}\right) \right) \end{align}
のはずであるが,これが
\begin{align} \boldsymbol{x} _ {2}^T \boldsymbol{\Lambda} _ {22} \boldsymbol{x} _ {2} -2 \left( \boldsymbol{\Lambda} _ {22} \boldsymbol{\mu} _ {2} +\boldsymbol{\Lambda} _ {21} \left(\boldsymbol{x} _ {1}-\boldsymbol{\mu} _ {1}\right) \right)\boldsymbol{x} _ {2} \end{align}
となっていた.
19/03/12追記:書籍版では以下のようになっているが,誤り.全ての項が二次形式になるはずであるが,後半が(二次形式)ベクトルの形になっている.
19/03/12追記2:これについてはサポートページの正誤表に記載されています.
\begin{align} \boldsymbol{x} _ {2}^T \boldsymbol{\Lambda} _ {22} \boldsymbol{x} _ {2} -2\boldsymbol{x} _ {2}^T \left( \boldsymbol{\Lambda} _ {22} \boldsymbol{\mu} _ {2} +\boldsymbol{\Lambda} _ {21} \left(\boldsymbol{x} _ {1}-\boldsymbol{\mu} _ {1}\right) \right)\boldsymbol{x} _ {2} \end{align}
式(2.58)(γ2版)式(2.57)(書籍版)以降,精度行列で表された正規分布
19/03/12追記:書籍版では修正されていました.
正しくは
\begin{align} p\left(\boldsymbol{x} _ 2|\boldsymbol{x} _ 1 \right) &\sim \mathcal{N} \left( \boldsymbol{\mu} _ {2} +\boldsymbol{\Lambda} _ {22}^{-1}\boldsymbol{\Lambda} _ {21} \left(\boldsymbol{x} _ {1}-\boldsymbol{\mu} _ {1}\right) , \boldsymbol{\Lambda} _ {22}^{-1} \right) \ \end{align}
だと思うが,
\begin{align} p\left(\boldsymbol{x} _ 2|\boldsymbol{x} _ 1 \right) &\sim \mathcal{N} \left( \boldsymbol{\mu} _ {2} +\boldsymbol{\Lambda} _ {22}^{-1}\boldsymbol{\Lambda} _ {21} \left(\boldsymbol{x} _ {1}-\boldsymbol{\mu} _ {1}\right) , \boldsymbol{\Lambda} _ {22} \right) \ \end{align}
となっていた.共分散行列はの逆行列
になるはずである.
混合モデルの導入
はじめに
須山ベイズ本を参考に,混合モデルの導入部分を勉強したノート.離散確率分布の復習も含む.隠れマルコフモデルについて学びたかったのだが,そのために混合モデルについて押さえようと思ったらそれなりのボリュームになってしまったので一旦記事としてまとめておく.
あくまでも勉強ノートなので,教科書ありきの文章である.これを解説として読んでもらうのではなく,須山本を読む上での補足資料として参考になれば幸いである.単なる写経ではなく,式変形は細かくやっていたりするので,そのあたり誰かの役に立つかもしれない.
参考文献
- 須山敦志,「機械学習スタートアップシリーズ ベイズ推論による機械学習入門
(KS情報科学専門書) Kindle版」,講談社,2017.
- 良い評判しか目にしない名著.書籍版とKindle版両方とも買ってしまった.これ自体を教科書として勉強できると同時に,他の本を読むときの参考書としても強力なので,読みたいときにすぐ読めるKindle版便利.
- Christopher M. Bishop. 2006. Pattern Recognition and Machine Learning (Information Science and Statistics). Springer-Verlag, Berlin, Heidelberg.
- いわゆるPRML.英語版はリンク先のとおりMicrosoftのサイトからダウンロードできます.日本語版は上巻しか持っておらず,上巻には混合モデルの話は含まれていない.全てが一体の英語版便利.
- 9章で混合モデルの話が扱われている.
")
機械学習スタートアップシリーズ ベイズ推論による機械学習入門 (KS情報科学専門書)
- 作者:須山 敦志
- 発売日: 2017/10/21
- メディア: 単行本(ソフトカバー)
")
Pattern Recognition and Machine Learning (Information Science and Statistics)
- 作者:Bishop, Christopher M.
- 発売日: 2006/08/17
- メディア: ハードカバー
予備知識
離散確率分布:ベルヌーイ分布とカテゴリ分布
混合モデルでは,データを構成するこの点たちは分布1から発生しており,他の点たちは分布2から発生しており・・・と,複数の異なる分布によってデータが構成されていると考える.データがどの分布から発生したのか,ということを考えるのはいわゆるクラスタリング問題であり,このとき有用になるのがベルヌーイ分布とカテゴリ分布である.これらを予備知識として復習しておこう.
ベルヌーイ分布は2つのクラスタのみを考えるケースであり,ベルヌーイ分布を次元に拡張したものがカテゴリ分布である.すなわちカテゴリ分布は
個のクラスタのうち,どのクラスタに所属するのかを示す確率分布になっている.
須山本ではカテゴリ分布と表記されているが,一般にはカテゴリカル分布と呼ばれるようである.マルチヌーイ分布という言い方もあるらしい.
クラスタ数2の場合:ベルヌーイ分布
まずベルヌーイ分布であるが,か
のどちらかを取る二値変数
の生成分布である.これは
から
までの連続値を取るパラメータ
によって形が決まり,次のように書く.
\begin{align} {\rm Bern}(x|\mu)=\mu^x(1-\mu)^{1-x} \end{align}
のときは
になるし,
のときは
になるから,これはつまり
の値は
が得られる確率そのものだ,ということである.冗長だが,折角なので具体的な数字を入れてどうなるか見ておこう.
の場合を考えてみると,
\begin{align}
{\rm Bern}(x|0.5)=0.5^x\times0.5^{1-x}
\end{align}
となって,
となる確率は
となる.逆に
となる確率も
\begin{align}
{\rm Bern}(1|0.5)=0.5^1\times0.5^{0}=0.5
\end{align}
となるから,この場合は
と
は半々の確率で得られるということになる.
クラスタ数Kの場合:カテゴリ分布
ベルヌーイ分布ではクラスタが2つの場合について考えたが,個の場合はどう表せるだろうか.
ここで変数を考える(これは後々見るように,混合分布の文脈では直接観測に引っかからない潜在変数となる).
このベクトルの要素は,すなわち
か
かどちらかの値を取る離散的な変数であり,かつ
を満たす.つまり,
番目が
であれば,他の要素は全て
ということになる.このようにしてクラスタへの所属を表すことを
of
表現と呼ぶ.
ベルヌーイ分布では1つのパラメータによって分布が決まっていた.カテゴリ分布では,これを
個に拡張して,混合比率
によって分布の形を決める.
であり,
を満たす.
が離散変数であるのに対して,
は連続値を取ることに注意しておこう.
以上で準備が整った.カテゴリ分布は,次のように書ける.
\begin{aligned} {\rm Cat}(\boldsymbol{s}|\boldsymbol{\pi})=\Pi _ {k=1}^{K} \pi _ {k}^{s _ {k}} \end{aligned}
クラスタ数の場合について考えてみよう.このとき潜在変数は
となるし,混合比率は
である.したがって
\begin{align} {\rm Cat}(\boldsymbol{s}| \boldsymbol{\pi}) &= \Pi _ {k=1}^K \pi_k^{s _ k} \\ &= \Pi _ {k=1}^2 \pi_k^{s _ k} \\ &= \pi _ 1^{s _ 1}\cdot\pi_2^{s _ 2} \\ &= \pi _ 1^{s _ 1}\cdot(1-\pi _ 1)^{1-s _ 1} \end{align}
となって,ベルヌーイ分布に一致することが確かめられた.
2つのクラスタのうち,1番目のクラスタが選ばれる確率を計算したいなら,だから,
\begin{align} {\rm Cat}(\boldsymbol{s}|\boldsymbol{\pi}) &= \pi _ 1^{s _ 1}\cdot(1-\pi _ 1)^{1-s _ 1} \\ &=\pi _ 1^{1}\cdot(1-\pi _ 1)^{0} \\ &=\pi _ 1 \end{align}
となってが残る.
と
が半々の確率で選ばれる場合,
である.ベルヌーイ分布と同様に,結局
によって
の各要素が出現する確率が決まることが確認できた.
連続確率分布:ベータ分布とディリクレ分布
カテゴリ分布を決めるのは混合比率であった.次はこの
を得る確率について考えたい.
は
から
までの値を取る連続変数であり,このような変数を生成する確率分布がベータ分布とディリクレ分布である.今回は知識として眺めるだけに留めておく.「そういうもん」と思って欲しい.
ベータ分布
ベルヌーイ分布で出て来たの分布を与えてくれるのがベータ分布である.パラメータ
と
を使って次のように書く.
は
と
の値に応じて決まる規格化係数で,ガンマ関数によって構成される.
ディリクレ分布
カテゴリ分布で出て来た混合比率の分布を与えてくれるのがディリクレ分布である.パラメータ
を使って次のように書く.
\begin{align} {\rm Dir}(\boldsymbol{\pi}|\boldsymbol{\alpha}) =C _ D(\boldsymbol{\alpha})\Pi _ {k=1}^K \pi_k^{\alpha _ k-1} \end{align}
規格化係数はやはりガンマ関数によって構成される.
混合モデル
混合モデルでは,データが複数の異なる分布によって生成していると考える.
データを生成する確率分布の個数(クラスタ数)をとして,
個のデータ
の生成過程を考えよう.
ちなみに,
の1点である
は多次元空間上の1つの点であり,これ自体がベクトルである.たとえば,3次元空間上にばらまかれている点の集団がデータ
であれば,その一つ一つの点は3次元ベクトルであって
のように書ける.
以下では混合モデルを考える上で道具となる量について見ていく.
クラスタの混合比率
データのうち,それぞれの分布(クラスタ)がどの程度含まれているか,から
までの値で表すことにする.これをベクトルとしてまとめたものが混合比率(mixture weight)
である.
ここで
である.また全体で
となるように
とする.さて,予備知識のところで見たように,
は"混合比率"なのだから,
から
までの連続値を取ることに注意しておこう.これに対して,この後出てくる潜在変数
はどのクラスタに属するかを
か
で表す離散的な量である.基本的なことではあるが確認のため記しておくと,このような離散的な集合は波括弧を用いて
で表す.何でこんなことをくどくど書くのかというと,単に私の脳が混乱したからにすぎない.
も確率変数であって,事前分布
に従って生成されるとする.
モデルパラメータ
たとえば各分布が正規分布の場合,平均値と分散がモデルパラメータとなる.分布ごとにパラメータは異なるから,番目の分布のパラメータセットをベクトル
で表す.正規分布の場合であれば,
となる.
は事前分布
に従って生成されるとする.
潜在変数
観測データのある点
が
個の分布のうちどれによって生成するかという対応関係を決める変数が
であり,潜在変数と呼ばれる.
であり,予備知識で見たとおり
of
表現によってどのクラスタに所属しているかを表す.これが
個分あるのだから,その集合を
と表す.
また,データがどのクラスタに所属しているか(どのクラスタから生成したか)?というのは,そのデータがどのモデルパラメータに対応しているのかを考えることと同じである.
グラフィカルモデル
ここで考えているデータの生成過程は下に示すグラフィカルモデルで表すことができる.
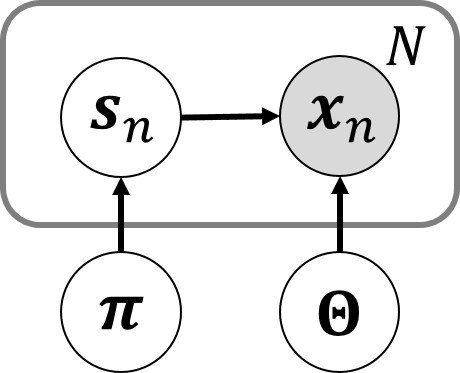
は
と
に依存する.注意しておくべきなのは,
と
の間には依存関係が無いということ.各クラスタの分布がどのような形になっているかということ(
)と,どの分布が選ばれるかということ(
)は無関係である.
余談であるが,図のように個の量を一つのノードで表し,それらを四角で囲ってから個数を
と記す省略表記方法はプレート表現(plate notation)と言われる.また,
が観測値であることはノードを塗りつぶすことによって示す.このあたりは須山本p.24や,PRMLの8章で解説がなされている.
混合分布の構成
がどのクラスタ(モデルパラメータ)に属するかは潜在変数
で決まるのであった.
は
とモデルパラメータ全体の集合
に依存して決まるので,
の生成確率は
と書ける.
予備知識として見たように,
個のクラスタについてのカテゴリ分布は次のように書けるのだった.
\begin{align} {\rm Cat}(\boldsymbol{s}|\boldsymbol{\pi})=\Pi _ {k=1}^K \pi _ k^{s _ k} \end{align}
これを参考にして,の生成確率は次のように書ける.
\begin{align} p(\boldsymbol{x} _ n|s _ n,\boldsymbol{\Theta})=\Pi _ {k=1}^K p(\boldsymbol{x} _ n|\boldsymbol{\theta} _ k)^{s _ {n,k}} \end{align}
となる.くどいようだが,やはりひとまず具体的に見ていこう.の場合を考えると,
なんだから,
\begin{align} p(\boldsymbol{x} _ n|s _ n,\boldsymbol{\Theta}) &=\Pi _ {k=1}^2 p(\boldsymbol{x} _ n|\boldsymbol{\theta} _ k)^{s _ {n,k}} \\ &=p(\boldsymbol{x} _ n|\boldsymbol{\theta} _ 1)^{s _ {n,1}}\cdot p(\boldsymbol{x} _ n|\boldsymbol{\theta} _ 2)^{1-s _ {n,1}} \end{align}
ということである.が1番目のクラスタから生成されたとすると,
だから,
\begin{align} p(\boldsymbol{x} _ n|s _ n,\boldsymbol{\Theta}) &=\Pi _ {k=1}^2 p(\boldsymbol{x} _ n|\boldsymbol{\theta} _ k)^{s _ {n,k}} \\ &=p(\boldsymbol{x} _ n|\boldsymbol{\theta} _ 1)^{s _ {n,1}}\cdot p(\boldsymbol{x} _ n|\boldsymbol{\theta} _ 2)^{1-s _ {n,1}} \\ &=p(\boldsymbol{x} _ n|\boldsymbol{\theta} _ 1)^{1}\cdot p(\boldsymbol{x} _ n|\boldsymbol{\theta} _ 2)^{0} \\ &=p(\boldsymbol{x} _ n|\boldsymbol{\theta} _ 1) \end{align}
となってが残る.
はあるモデルパラメータを選んだときに
が得られる確率である.モデルが正規分布だとすればモデルパラメータは
であり,
に対して,
\begin{align} p(\boldsymbol{x} _ n|\boldsymbol{\theta} _ k) = \mathcal{N}(\boldsymbol{x} _ n|\boldsymbol{\mu} _ k, \boldsymbol{\Sigma} _ k ) \end{align}
となる.
さて,潜在変数が
であるか
であるかの確率は混合比率
で決まり,
\begin{align} {\rm Cat}(\boldsymbol{s}|\boldsymbol{\pi})=\Pi _ {k=1}^K \pi _ k^{s _ k} \end{align}
だった.そしてが
か,
かといったように,
の各要素がどのような値を取るかというのは事前分布
によって決まると考えるのだった.この事前分布としてディリクレ分布を使う.すなわち
である.
同時分布
以上で下準備が終わった.それでは個のデータ
,潜在変数
,モデルパラメータ
,混合比率
の同時分布
を考える.
乗法定理によって条件付き分布に書き換えていくと,
\begin{align} p(\boldsymbol{X},\boldsymbol{S},\boldsymbol{\Theta},\boldsymbol{\pi}) &= p(\boldsymbol{X},\boldsymbol{S},\boldsymbol{\Theta}|\boldsymbol{\pi})p(\boldsymbol{\pi}) \\ &= p(\boldsymbol{X},\boldsymbol{\Theta}|\boldsymbol{S},\boldsymbol{\pi})p(\boldsymbol{S}|\boldsymbol{\pi})p(\boldsymbol{\pi}) \\ &= p(\boldsymbol{X}|\boldsymbol{S},\boldsymbol{\Theta}, \boldsymbol{\pi})p(\boldsymbol{\Theta}|\boldsymbol{S},\boldsymbol{\pi})p(\boldsymbol{S}|\boldsymbol{\pi})p(\boldsymbol{\pi}) \\ \end{align}
ここでグラフィカルモデルを思い出す.
図から明らかなように,と
の間には依存関係が無い.
は
にも
にも無関係なのだから,上の同時分布の式で出て来た
は,単なる
に等しい.つまり,
\begin{align} p(\boldsymbol{\Theta}|\boldsymbol{S},\boldsymbol{\pi}) = p(\boldsymbol{\Theta}) \end{align}
である.もう一つ,図から明らかなように,は
と
に依存するけれど
には直接依存しない.したがって,
\begin{align} p(\boldsymbol{X}|\boldsymbol{S},\boldsymbol{\Theta}, \boldsymbol{\pi}) = p(\boldsymbol{X}|\boldsymbol{S},\boldsymbol{\Theta}) \end{align}
となる.というわけで同時分布の式は,次のように書き換えられる.
\begin{align} p(\boldsymbol{X},\boldsymbol{S},\boldsymbol{\Theta},\boldsymbol{\pi}) &= p(\boldsymbol{X}|\boldsymbol{S},\boldsymbol{\Theta}, \boldsymbol{\pi})p(\boldsymbol{\Theta}|\boldsymbol{S},\boldsymbol{\pi})p(\boldsymbol{S}|\boldsymbol{\pi})p(\boldsymbol{\pi}) \\ &= p(\boldsymbol{X}|\boldsymbol{S},\boldsymbol{\Theta})p(\boldsymbol{\Theta})p(\boldsymbol{S}|\boldsymbol{\pi})p(\boldsymbol{\pi}) \\ \end{align}
ここで,は
\begin{align} p(\boldsymbol{X}|\boldsymbol{S},\boldsymbol{\Theta}) &= p(\boldsymbol{x} _ 1,\cdots, \boldsymbol{x} _ N|\boldsymbol{s} _ 1,\cdots, \boldsymbol{s} _ N,\boldsymbol{\Theta}) \\ &=p(\boldsymbol{x} _ 1|\boldsymbol{s} _ 1,\cdots, \boldsymbol{s} _ N,\boldsymbol{\Theta}) \cdots p(\boldsymbol{x} _ N|\boldsymbol{s} _ 1,\cdots, \boldsymbol{s} _ N,\boldsymbol{\Theta}) \\ \end{align}
であって,は
のうち
にしか依存しないということを考慮すると,
\begin{align} p(\boldsymbol{X}|\boldsymbol{S},\boldsymbol{\Theta}) &= p(\boldsymbol{x} _ 1,\cdots, \boldsymbol{x} _ N|\boldsymbol{s} _ 1,\cdots, \boldsymbol{s} _ N,\boldsymbol{\Theta}) \\ &=p(\boldsymbol{x} _ 1|\boldsymbol{s} _ 1,\cdots, \boldsymbol{s} _ N,\boldsymbol{\Theta}) \cdots p(\boldsymbol{x} _ N|\boldsymbol{s} _ 1,\cdots, \boldsymbol{s} _ N,\boldsymbol{\Theta}) \\ &=p(\boldsymbol{x} _ 1|\boldsymbol{s} _ 1,\boldsymbol{\Theta}) \cdots p(\boldsymbol{x} _ N|\boldsymbol{s} _ N,\boldsymbol{\Theta}) \\ &= \Pi _ {n=1}^N p(\boldsymbol{x} _ n|\boldsymbol{s} _ n,\boldsymbol{\Theta}) \end{align}
についても同様.
\begin{align} p(\boldsymbol{S}|\boldsymbol{\pi}) &= p(\boldsymbol{s} _ 1,\cdots, \boldsymbol{s} _ N|\boldsymbol{\pi}) \\ &=p(\boldsymbol{s} _ 1|\boldsymbol{\pi}) \cdots p(\boldsymbol{s} _ N|\boldsymbol{\pi})\\ &= \Pi _ {n=1}^N p(\boldsymbol{s} _ n|\boldsymbol{\pi}) \end{align}
次にであるが,
\begin{align} p(\boldsymbol{\Theta}) &= p(\boldsymbol{\theta} _ 1,\cdots, \boldsymbol{\theta} _ K) \\ &=p(\boldsymbol{\theta} _ 1) \cdots p(\boldsymbol{\theta} _ k)\\ &= \Pi _ {k=1}^K p(\boldsymbol{\theta} _ k) \end{align}
したがって同時分布の式は
\begin{align} p(\boldsymbol{X},\boldsymbol{S},\boldsymbol{\Theta},\boldsymbol{\pi}) &= p(\boldsymbol{X}|\boldsymbol{S},\boldsymbol{\Theta}, \boldsymbol{\pi})p(\boldsymbol{\Theta}|\boldsymbol{S},\boldsymbol{\pi})p(\boldsymbol{S}|\boldsymbol{\pi})p(\boldsymbol{\pi}) \\ &= p(\boldsymbol{X}|\boldsymbol{S},\boldsymbol{\Theta})p(\boldsymbol{\Theta})p(\boldsymbol{S}|\boldsymbol{\pi})p(\boldsymbol{\pi}) \\ &= \left( \Pi _ {n=1}^N p(\boldsymbol{x} _ n|\boldsymbol{s} _ n,\boldsymbol{\Theta}) p(\boldsymbol{s} _ n|\boldsymbol{\pi}) \right) \left( \Pi _ {k=1}^K p(\boldsymbol{\theta} _ k) \right) p(\boldsymbol{\pi}) \end{align}
こうして須山本の式(4.5)に辿り着きました.めでたし.
事後分布
データが所属するクラスタの推定を行いたい場合,事後分布を求めれば良い.
\begin{align} p(\boldsymbol{S}|\boldsymbol{X}) &=\int \int p(\boldsymbol{S},\boldsymbol{\Theta},\boldsymbol{\pi}|\boldsymbol{X}){\rm d}\boldsymbol{\Theta}{\rm d}\boldsymbol{\pi}\\ p(\boldsymbol{S},\boldsymbol{\Theta},\boldsymbol{\pi}|\boldsymbol{X}) &= \frac{p(\boldsymbol{X},\boldsymbol{S},\boldsymbol{\Theta},\boldsymbol{\pi})} {p(\boldsymbol{X})} \end{align}
であるが,この計算は一般に困難とされている.その解決法として,なんらかの近似アルゴリズムによって推論を行おう,ということでMCMCや変分推論に話が繋がっていく.
【強化学習】Bellman方程式の導出
はじめに
Qrunchに投稿した記事に少し追記したものです.というのも,現状Qrunchだと外部からの検索で上手く引っかからないよう(つまりGoogle検索で出てこない).QrunchはQrunchコミュニティ内での気軽な技術系情報共有を目的にしているところがコンセプトっぽいので,あえて閉鎖的なコンテンツにしているということなのかもしれません.個人の勉強メモとして引き続きQrunchも活用していきたいと思っていますが,多少なりとも誰かの役に立ちそうな内容のものは積極的に外部に公開しても良いのかなと考えて,はてなも活用していこうと思っています.(Qrunchには「クロス投稿」機能があるので,それを使うのが良さそう)
モチベーション
強化学習のお勉強のため,Pythonで実装しようぜ系の本をしばらく読んでいたのですが,肝心のBellman方程式はわりとサラッと導出されていて,自分で手を動かして式を追ってみないとなんだかよくわからない.そうするにあたって瀧先生の深層学習本の強化学習の章における説明が個人的に分かりやすかったので,これを参考にBellman方程式導出の過程をまとめておく.この記事の目的はあくまでもBellman方程式を導出するまでのひとつひとつの式変形のステップを省略せずにまとめておくことなので,強化学習そのものについては次節で挙げている書籍を参考にされてください.
Bellman方程式ってなに
Bellman方程式とは,価値関数を状態と次の状態
についての漸化式として表したものである.再帰的に価値関数を表すことの必要性は書籍「Pythonで学ぶ強化学習」に易しい解説があり,分かりやすいと思う.
Bellman方程式の導出の流れ
量の書き換えがいくつか出て来て最初は混乱したのですが,やっていることは単純で,以下の二点にまとめられる.
報酬の再帰性を使って,価値関数を漸化式の形に書く.
マルコフ性によって依存関係を整える.
参考書籍
メイン
サブ
Richard S.Sutton,Andrew G.Barto,三上貞芳(訳),皆川 雅章(訳),「強化学習」,森北出版,2000.
久保隆宏,「機械学習スタートアップシリーズ Pythonで学ぶ強化学習 入門から実践まで (KS情報科学専門書) 」,講談社,2019.
計算ルール(確率,期待値の基本)
Bellman方程式の導出で必要になる計算ルールを予備知識としてまとめておく. これらに加えて,強化学習の問題設定がマルコフ決定過程であることを利用して話が進んでいきます. 確率の基礎にまつわる話は個人的に「プログラミングのための確率統計」が直感的で分かりやすいので,脳が混乱したときには読み返している.
周辺化
基本
ですよね.同時分布をある確率変数について和を取れば,括弧からそいつが消えます.得られたを周辺分布という.
例
Bellman方程式の導出では,たとえば遷移確率を周辺化によって次のように式変形する. 強化学習では基本的に条件付き分布ばかりを扱いますが,上で見た基本式のおしりに条件がくっついてるだけ.
同時確率と条件付き確率の関係(乗法定理)
基本
例
これを使って先ほどの周辺化の例を,
というように変形していったりする.
条件付き期待値
基本1
条件付き期待値の定義はこう.
基本2
こうなることを一応確認しておく.
\begin{align} \sum_aE[Y|a]P(a) &= \sum_a\sum_bbP(b|a)P(a) \\ &= \sum_a\sum_bbP(a,b) \\ &= \sum_bb\left(\sum_aP(a,b)\right) \\ &= \sum_bbP(b) \\ &= E[Y=b] \end{align}
例
本題
登場人物(強化学習に出てくる基本概念)
遷移確率
状態で行動
を取ったときに状態
に遷移する確率.
取り得る全ての行動について足し合わせると(計算ルールのところで確認した周辺化),状態から
への遷移確率になる.
ここで,状態において行動
を選択する確率は方策と呼ばれ,特別に
と書く.
利得(累積報酬)
は割引率.累積報酬とか割引報酬和,割引累積報酬なんて呼ぶのが意味が分かりやすくて好きだが,単に報酬や利得と呼ばれることも多いっぽい.これは第1項と残りを分けることで再帰的に書くことができる.
ちなみには,行動
によって,状態
から状態
になったときに得る即時報酬.貰うタイミングは時刻
.
即時報酬の期待値
大文字ので書いているが,上の累積報酬ではなく時刻
の即時報酬についての話である.
上で書いているようになので,右辺の意味は以下のとおり.
状態での報酬の期待値は,上記の量を行動
と次の状態
について期待値を取る.要するに,行動や次の状態にかかわらず,「ただ状態
にいるだけで」これくらいの報酬が得られるだろうと期待できるということ.ここで重みとして用いる確率は,
を取る確率と,
となる確率なのだから,すなわち方策と遷移確率ですね.
価値関数
状態価値関数
ある状態であったとき,得られるであろう累積報酬
の期待値を状態価値関数と呼ぶ.これによって各状態の良し悪し(価値)が評価できる.
]
ここでの添字
と
の意味は,さきほど出て来た即時報酬の期待値と同様に,遷移確率
と方策
で期待値を取っているよということ.
行動価値関数
状態において行動
を取ったときの累積報酬
の期待値.
との関係
計算ルールの条件付き期待値のところで見たように,
と書き換えられる.最右辺の条件付き期待値はまさにだから,
ようやくBellman方程式へ
状態価値関数についてのBellman方程式
さきほどの「と
の関係」で出て来たように,
予備知識の計算ルールである条件付き期待値の性質を使って,条件にを追加する.
するとVは
となりますね.
累積報酬を再帰的に書くと
だったから,これを上の式に入れてやる.そうすると,
となって,即時報酬の期待値が出て来た.これは上で見たように
]
と表していたので,これを使ってさらに書き換えると
ここで出て来たは
なのでした.したがって
この第2項目には遷移確率が含まれているから,
さてここで,は状態
から
となった時点以降の累積報酬である.これは状態
と行動
には依存しない(マルコフ性).
そういうわけで上の式の中の条件付き期待値は,
となり,これは結局,次の状態での状態価値関数
であった.
したがって最終的に,
となって,これが状態価値関数についてのBellman方程式です.
行動価値関数についてのBellman方程式
行動価値関数は
]
なのでした.これをに対してやったのと同様に,計算ルールである条件付き期待値の性質を使って
について和を取ります.
それから
を代入して二つの項に分けます.
そうすると第1項には
が現れます.
第2項はマルコフ性によって条件付き期待値から
と
が除かれて,その結果
が出て来る.
「と
の関係」で見たように
だったから,
である.これを使って書き換えれば,
となる.これが行動価値関数についてのBellman方程式.
Sutton本との比較
Sutton本と瀧深層学習本はそれぞれ量の表記が異なるので,同じ方程式であるのか一目見るだけでは私は脳のメモリが足りずよく分からない.というわけで互いに同一の結果を得ていることを確認しておく.Sutton本だとp.76の式(3.10)でについてのBellman方程式が示されている.
まずであるが,p.56にて説明がなされており,これはこれまで見てきた
と同じものである.Sutton本では,
が
と
の関数であることを明示した表記を取っていると私は解釈した.
次に
と
はp.72の式(3.6)と(3.7)で説明がされているように,
である.ここでと書かれているのは,
ということである.
以上を踏まえて,瀧深層学習本での表記に合わせるようにSutton本のBellman方程式を書き換えてみる.
この時点で,あぁ,同じやんけ,と安心するのだが,折角なので最後まで書き換える.ここで以下の3つを思い出す.
これらを使って書き換えると,
となって,瀧深層学習本のBellman方程式に一致した.安心した.