混合モデルの導入
はじめに
須山ベイズ本を参考に,混合モデルの導入部分を勉強したノート.離散確率分布の復習も含む.隠れマルコフモデルについて学びたかったのだが,そのために混合モデルについて押さえようと思ったらそれなりのボリュームになってしまったので一旦記事としてまとめておく.
あくまでも勉強ノートなので,教科書ありきの文章である.これを解説として読んでもらうのではなく,須山本を読む上での補足資料として参考になれば幸いである.単なる写経ではなく,式変形は細かくやっていたりするので,そのあたり誰かの役に立つかもしれない.
参考文献
- 須山敦志,「機械学習スタートアップシリーズ ベイズ推論による機械学習入門
(KS情報科学専門書) Kindle版」,講談社,2017.
- 良い評判しか目にしない名著.書籍版とKindle版両方とも買ってしまった.これ自体を教科書として勉強できると同時に,他の本を読むときの参考書としても強力なので,読みたいときにすぐ読めるKindle版便利.
- Christopher M. Bishop. 2006. Pattern Recognition and Machine Learning (Information Science and Statistics). Springer-Verlag, Berlin, Heidelberg.
- いわゆるPRML.英語版はリンク先のとおりMicrosoftのサイトからダウンロードできます.日本語版は上巻しか持っておらず,上巻には混合モデルの話は含まれていない.全てが一体の英語版便利.
- 9章で混合モデルの話が扱われている.
")
機械学習スタートアップシリーズ ベイズ推論による機械学習入門 (KS情報科学専門書)
- 作者:須山 敦志
- 発売日: 2017/10/21
- メディア: 単行本(ソフトカバー)
")
Pattern Recognition and Machine Learning (Information Science and Statistics)
- 作者:Bishop, Christopher M.
- 発売日: 2006/08/17
- メディア: ハードカバー
予備知識
離散確率分布:ベルヌーイ分布とカテゴリ分布
混合モデルでは,データを構成するこの点たちは分布1から発生しており,他の点たちは分布2から発生しており・・・と,複数の異なる分布によってデータが構成されていると考える.データがどの分布から発生したのか,ということを考えるのはいわゆるクラスタリング問題であり,このとき有用になるのがベルヌーイ分布とカテゴリ分布である.これらを予備知識として復習しておこう.
ベルヌーイ分布は2つのクラスタのみを考えるケースであり,ベルヌーイ分布を次元に拡張したものがカテゴリ分布である.すなわちカテゴリ分布は
個のクラスタのうち,どのクラスタに所属するのかを示す確率分布になっている.
須山本ではカテゴリ分布と表記されているが,一般にはカテゴリカル分布と呼ばれるようである.マルチヌーイ分布という言い方もあるらしい.
クラスタ数2の場合:ベルヌーイ分布
まずベルヌーイ分布であるが,か
のどちらかを取る二値変数
の生成分布である.これは
から
までの連続値を取るパラメータ
によって形が決まり,次のように書く.
\begin{align} {\rm Bern}(x|\mu)=\mu^x(1-\mu)^{1-x} \end{align}
のときは
になるし,
のときは
になるから,これはつまり
の値は
が得られる確率そのものだ,ということである.冗長だが,折角なので具体的な数字を入れてどうなるか見ておこう.
の場合を考えてみると,
\begin{align}
{\rm Bern}(x|0.5)=0.5^x\times0.5^{1-x}
\end{align}
となって,
となる確率は
となる.逆に
となる確率も
\begin{align}
{\rm Bern}(1|0.5)=0.5^1\times0.5^{0}=0.5
\end{align}
となるから,この場合は
と
は半々の確率で得られるということになる.
クラスタ数Kの場合:カテゴリ分布
ベルヌーイ分布ではクラスタが2つの場合について考えたが,個の場合はどう表せるだろうか.
ここで変数を考える(これは後々見るように,混合分布の文脈では直接観測に引っかからない潜在変数となる).
このベクトルの要素は,すなわち
か
かどちらかの値を取る離散的な変数であり,かつ
を満たす.つまり,
番目が
であれば,他の要素は全て
ということになる.このようにしてクラスタへの所属を表すことを
of
表現と呼ぶ.
ベルヌーイ分布では1つのパラメータによって分布が決まっていた.カテゴリ分布では,これを
個に拡張して,混合比率
によって分布の形を決める.
であり,
を満たす.
が離散変数であるのに対して,
は連続値を取ることに注意しておこう.
以上で準備が整った.カテゴリ分布は,次のように書ける.
\begin{aligned} {\rm Cat}(\boldsymbol{s}|\boldsymbol{\pi})=\Pi _ {k=1}^{K} \pi _ {k}^{s _ {k}} \end{aligned}
クラスタ数の場合について考えてみよう.このとき潜在変数は
となるし,混合比率は
である.したがって
\begin{align} {\rm Cat}(\boldsymbol{s}| \boldsymbol{\pi}) &= \Pi _ {k=1}^K \pi_k^{s _ k} \\ &= \Pi _ {k=1}^2 \pi_k^{s _ k} \\ &= \pi _ 1^{s _ 1}\cdot\pi_2^{s _ 2} \\ &= \pi _ 1^{s _ 1}\cdot(1-\pi _ 1)^{1-s _ 1} \end{align}
となって,ベルヌーイ分布に一致することが確かめられた.
2つのクラスタのうち,1番目のクラスタが選ばれる確率を計算したいなら,だから,
\begin{align} {\rm Cat}(\boldsymbol{s}|\boldsymbol{\pi}) &= \pi _ 1^{s _ 1}\cdot(1-\pi _ 1)^{1-s _ 1} \\ &=\pi _ 1^{1}\cdot(1-\pi _ 1)^{0} \\ &=\pi _ 1 \end{align}
となってが残る.
と
が半々の確率で選ばれる場合,
である.ベルヌーイ分布と同様に,結局
によって
の各要素が出現する確率が決まることが確認できた.
連続確率分布:ベータ分布とディリクレ分布
カテゴリ分布を決めるのは混合比率であった.次はこの
を得る確率について考えたい.
は
から
までの値を取る連続変数であり,このような変数を生成する確率分布がベータ分布とディリクレ分布である.今回は知識として眺めるだけに留めておく.「そういうもん」と思って欲しい.
ベータ分布
ベルヌーイ分布で出て来たの分布を与えてくれるのがベータ分布である.パラメータ
と
を使って次のように書く.
は
と
の値に応じて決まる規格化係数で,ガンマ関数によって構成される.
ディリクレ分布
カテゴリ分布で出て来た混合比率の分布を与えてくれるのがディリクレ分布である.パラメータ
を使って次のように書く.
\begin{align} {\rm Dir}(\boldsymbol{\pi}|\boldsymbol{\alpha}) =C _ D(\boldsymbol{\alpha})\Pi _ {k=1}^K \pi_k^{\alpha _ k-1} \end{align}
規格化係数はやはりガンマ関数によって構成される.
混合モデル
混合モデルでは,データが複数の異なる分布によって生成していると考える.
データを生成する確率分布の個数(クラスタ数)をとして,
個のデータ
の生成過程を考えよう.
ちなみに,
の1点である
は多次元空間上の1つの点であり,これ自体がベクトルである.たとえば,3次元空間上にばらまかれている点の集団がデータ
であれば,その一つ一つの点は3次元ベクトルであって
のように書ける.
以下では混合モデルを考える上で道具となる量について見ていく.
クラスタの混合比率
データのうち,それぞれの分布(クラスタ)がどの程度含まれているか,から
までの値で表すことにする.これをベクトルとしてまとめたものが混合比率(mixture weight)
である.
ここで
である.また全体で
となるように
とする.さて,予備知識のところで見たように,
は"混合比率"なのだから,
から
までの連続値を取ることに注意しておこう.これに対して,この後出てくる潜在変数
はどのクラスタに属するかを
か
で表す離散的な量である.基本的なことではあるが確認のため記しておくと,このような離散的な集合は波括弧を用いて
で表す.何でこんなことをくどくど書くのかというと,単に私の脳が混乱したからにすぎない.
も確率変数であって,事前分布
に従って生成されるとする.
モデルパラメータ
たとえば各分布が正規分布の場合,平均値と分散がモデルパラメータとなる.分布ごとにパラメータは異なるから,番目の分布のパラメータセットをベクトル
で表す.正規分布の場合であれば,
となる.
は事前分布
に従って生成されるとする.
潜在変数
観測データのある点
が
個の分布のうちどれによって生成するかという対応関係を決める変数が
であり,潜在変数と呼ばれる.
であり,予備知識で見たとおり
of
表現によってどのクラスタに所属しているかを表す.これが
個分あるのだから,その集合を
と表す.
また,データがどのクラスタに所属しているか(どのクラスタから生成したか)?というのは,そのデータがどのモデルパラメータに対応しているのかを考えることと同じである.
グラフィカルモデル
ここで考えているデータの生成過程は下に示すグラフィカルモデルで表すことができる.
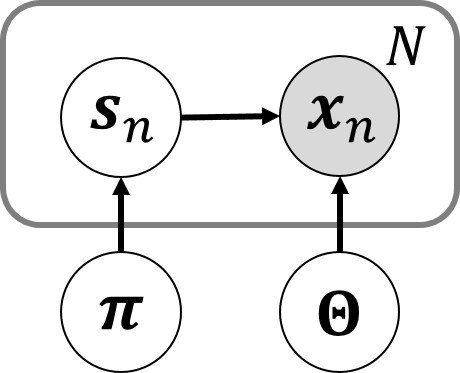
は
と
に依存する.注意しておくべきなのは,
と
の間には依存関係が無いということ.各クラスタの分布がどのような形になっているかということ(
)と,どの分布が選ばれるかということ(
)は無関係である.
余談であるが,図のように個の量を一つのノードで表し,それらを四角で囲ってから個数を
と記す省略表記方法はプレート表現(plate notation)と言われる.また,
が観測値であることはノードを塗りつぶすことによって示す.このあたりは須山本p.24や,PRMLの8章で解説がなされている.
混合分布の構成
がどのクラスタ(モデルパラメータ)に属するかは潜在変数
で決まるのであった.
は
とモデルパラメータ全体の集合
に依存して決まるので,
の生成確率は
と書ける.
予備知識として見たように,
個のクラスタについてのカテゴリ分布は次のように書けるのだった.
\begin{align} {\rm Cat}(\boldsymbol{s}|\boldsymbol{\pi})=\Pi _ {k=1}^K \pi _ k^{s _ k} \end{align}
これを参考にして,の生成確率は次のように書ける.
\begin{align} p(\boldsymbol{x} _ n|s _ n,\boldsymbol{\Theta})=\Pi _ {k=1}^K p(\boldsymbol{x} _ n|\boldsymbol{\theta} _ k)^{s _ {n,k}} \end{align}
となる.くどいようだが,やはりひとまず具体的に見ていこう.の場合を考えると,
なんだから,
\begin{align} p(\boldsymbol{x} _ n|s _ n,\boldsymbol{\Theta}) &=\Pi _ {k=1}^2 p(\boldsymbol{x} _ n|\boldsymbol{\theta} _ k)^{s _ {n,k}} \\ &=p(\boldsymbol{x} _ n|\boldsymbol{\theta} _ 1)^{s _ {n,1}}\cdot p(\boldsymbol{x} _ n|\boldsymbol{\theta} _ 2)^{1-s _ {n,1}} \end{align}
ということである.が1番目のクラスタから生成されたとすると,
だから,
\begin{align} p(\boldsymbol{x} _ n|s _ n,\boldsymbol{\Theta}) &=\Pi _ {k=1}^2 p(\boldsymbol{x} _ n|\boldsymbol{\theta} _ k)^{s _ {n,k}} \\ &=p(\boldsymbol{x} _ n|\boldsymbol{\theta} _ 1)^{s _ {n,1}}\cdot p(\boldsymbol{x} _ n|\boldsymbol{\theta} _ 2)^{1-s _ {n,1}} \\ &=p(\boldsymbol{x} _ n|\boldsymbol{\theta} _ 1)^{1}\cdot p(\boldsymbol{x} _ n|\boldsymbol{\theta} _ 2)^{0} \\ &=p(\boldsymbol{x} _ n|\boldsymbol{\theta} _ 1) \end{align}
となってが残る.
はあるモデルパラメータを選んだときに
が得られる確率である.モデルが正規分布だとすればモデルパラメータは
であり,
に対して,
\begin{align} p(\boldsymbol{x} _ n|\boldsymbol{\theta} _ k) = \mathcal{N}(\boldsymbol{x} _ n|\boldsymbol{\mu} _ k, \boldsymbol{\Sigma} _ k ) \end{align}
となる.
さて,潜在変数が
であるか
であるかの確率は混合比率
で決まり,
\begin{align} {\rm Cat}(\boldsymbol{s}|\boldsymbol{\pi})=\Pi _ {k=1}^K \pi _ k^{s _ k} \end{align}
だった.そしてが
か,
かといったように,
の各要素がどのような値を取るかというのは事前分布
によって決まると考えるのだった.この事前分布としてディリクレ分布を使う.すなわち
である.
同時分布
以上で下準備が終わった.それでは個のデータ
,潜在変数
,モデルパラメータ
,混合比率
の同時分布
を考える.
乗法定理によって条件付き分布に書き換えていくと,
\begin{align} p(\boldsymbol{X},\boldsymbol{S},\boldsymbol{\Theta},\boldsymbol{\pi}) &= p(\boldsymbol{X},\boldsymbol{S},\boldsymbol{\Theta}|\boldsymbol{\pi})p(\boldsymbol{\pi}) \\ &= p(\boldsymbol{X},\boldsymbol{\Theta}|\boldsymbol{S},\boldsymbol{\pi})p(\boldsymbol{S}|\boldsymbol{\pi})p(\boldsymbol{\pi}) \\ &= p(\boldsymbol{X}|\boldsymbol{S},\boldsymbol{\Theta}, \boldsymbol{\pi})p(\boldsymbol{\Theta}|\boldsymbol{S},\boldsymbol{\pi})p(\boldsymbol{S}|\boldsymbol{\pi})p(\boldsymbol{\pi}) \\ \end{align}
ここでグラフィカルモデルを思い出す.
図から明らかなように,と
の間には依存関係が無い.
は
にも
にも無関係なのだから,上の同時分布の式で出て来た
は,単なる
に等しい.つまり,
\begin{align} p(\boldsymbol{\Theta}|\boldsymbol{S},\boldsymbol{\pi}) = p(\boldsymbol{\Theta}) \end{align}
である.もう一つ,図から明らかなように,は
と
に依存するけれど
には直接依存しない.したがって,
\begin{align} p(\boldsymbol{X}|\boldsymbol{S},\boldsymbol{\Theta}, \boldsymbol{\pi}) = p(\boldsymbol{X}|\boldsymbol{S},\boldsymbol{\Theta}) \end{align}
となる.というわけで同時分布の式は,次のように書き換えられる.
\begin{align} p(\boldsymbol{X},\boldsymbol{S},\boldsymbol{\Theta},\boldsymbol{\pi}) &= p(\boldsymbol{X}|\boldsymbol{S},\boldsymbol{\Theta}, \boldsymbol{\pi})p(\boldsymbol{\Theta}|\boldsymbol{S},\boldsymbol{\pi})p(\boldsymbol{S}|\boldsymbol{\pi})p(\boldsymbol{\pi}) \\ &= p(\boldsymbol{X}|\boldsymbol{S},\boldsymbol{\Theta})p(\boldsymbol{\Theta})p(\boldsymbol{S}|\boldsymbol{\pi})p(\boldsymbol{\pi}) \\ \end{align}
ここで,は
\begin{align} p(\boldsymbol{X}|\boldsymbol{S},\boldsymbol{\Theta}) &= p(\boldsymbol{x} _ 1,\cdots, \boldsymbol{x} _ N|\boldsymbol{s} _ 1,\cdots, \boldsymbol{s} _ N,\boldsymbol{\Theta}) \\ &=p(\boldsymbol{x} _ 1|\boldsymbol{s} _ 1,\cdots, \boldsymbol{s} _ N,\boldsymbol{\Theta}) \cdots p(\boldsymbol{x} _ N|\boldsymbol{s} _ 1,\cdots, \boldsymbol{s} _ N,\boldsymbol{\Theta}) \\ \end{align}
であって,は
のうち
にしか依存しないということを考慮すると,
\begin{align} p(\boldsymbol{X}|\boldsymbol{S},\boldsymbol{\Theta}) &= p(\boldsymbol{x} _ 1,\cdots, \boldsymbol{x} _ N|\boldsymbol{s} _ 1,\cdots, \boldsymbol{s} _ N,\boldsymbol{\Theta}) \\ &=p(\boldsymbol{x} _ 1|\boldsymbol{s} _ 1,\cdots, \boldsymbol{s} _ N,\boldsymbol{\Theta}) \cdots p(\boldsymbol{x} _ N|\boldsymbol{s} _ 1,\cdots, \boldsymbol{s} _ N,\boldsymbol{\Theta}) \\ &=p(\boldsymbol{x} _ 1|\boldsymbol{s} _ 1,\boldsymbol{\Theta}) \cdots p(\boldsymbol{x} _ N|\boldsymbol{s} _ N,\boldsymbol{\Theta}) \\ &= \Pi _ {n=1}^N p(\boldsymbol{x} _ n|\boldsymbol{s} _ n,\boldsymbol{\Theta}) \end{align}
についても同様.
\begin{align} p(\boldsymbol{S}|\boldsymbol{\pi}) &= p(\boldsymbol{s} _ 1,\cdots, \boldsymbol{s} _ N|\boldsymbol{\pi}) \\ &=p(\boldsymbol{s} _ 1|\boldsymbol{\pi}) \cdots p(\boldsymbol{s} _ N|\boldsymbol{\pi})\\ &= \Pi _ {n=1}^N p(\boldsymbol{s} _ n|\boldsymbol{\pi}) \end{align}
次にであるが,
\begin{align} p(\boldsymbol{\Theta}) &= p(\boldsymbol{\theta} _ 1,\cdots, \boldsymbol{\theta} _ K) \\ &=p(\boldsymbol{\theta} _ 1) \cdots p(\boldsymbol{\theta} _ k)\\ &= \Pi _ {k=1}^K p(\boldsymbol{\theta} _ k) \end{align}
したがって同時分布の式は
\begin{align} p(\boldsymbol{X},\boldsymbol{S},\boldsymbol{\Theta},\boldsymbol{\pi}) &= p(\boldsymbol{X}|\boldsymbol{S},\boldsymbol{\Theta}, \boldsymbol{\pi})p(\boldsymbol{\Theta}|\boldsymbol{S},\boldsymbol{\pi})p(\boldsymbol{S}|\boldsymbol{\pi})p(\boldsymbol{\pi}) \\ &= p(\boldsymbol{X}|\boldsymbol{S},\boldsymbol{\Theta})p(\boldsymbol{\Theta})p(\boldsymbol{S}|\boldsymbol{\pi})p(\boldsymbol{\pi}) \\ &= \left( \Pi _ {n=1}^N p(\boldsymbol{x} _ n|\boldsymbol{s} _ n,\boldsymbol{\Theta}) p(\boldsymbol{s} _ n|\boldsymbol{\pi}) \right) \left( \Pi _ {k=1}^K p(\boldsymbol{\theta} _ k) \right) p(\boldsymbol{\pi}) \end{align}
こうして須山本の式(4.5)に辿り着きました.めでたし.
事後分布
データが所属するクラスタの推定を行いたい場合,事後分布を求めれば良い.
\begin{align} p(\boldsymbol{S}|\boldsymbol{X}) &=\int \int p(\boldsymbol{S},\boldsymbol{\Theta},\boldsymbol{\pi}|\boldsymbol{X}){\rm d}\boldsymbol{\Theta}{\rm d}\boldsymbol{\pi}\\ p(\boldsymbol{S},\boldsymbol{\Theta},\boldsymbol{\pi}|\boldsymbol{X}) &= \frac{p(\boldsymbol{X},\boldsymbol{S},\boldsymbol{\Theta},\boldsymbol{\pi})} {p(\boldsymbol{X})} \end{align}
であるが,この計算は一般に困難とされている.その解決法として,なんらかの近似アルゴリズムによって推論を行おう,ということでMCMCや変分推論に話が繋がっていく.